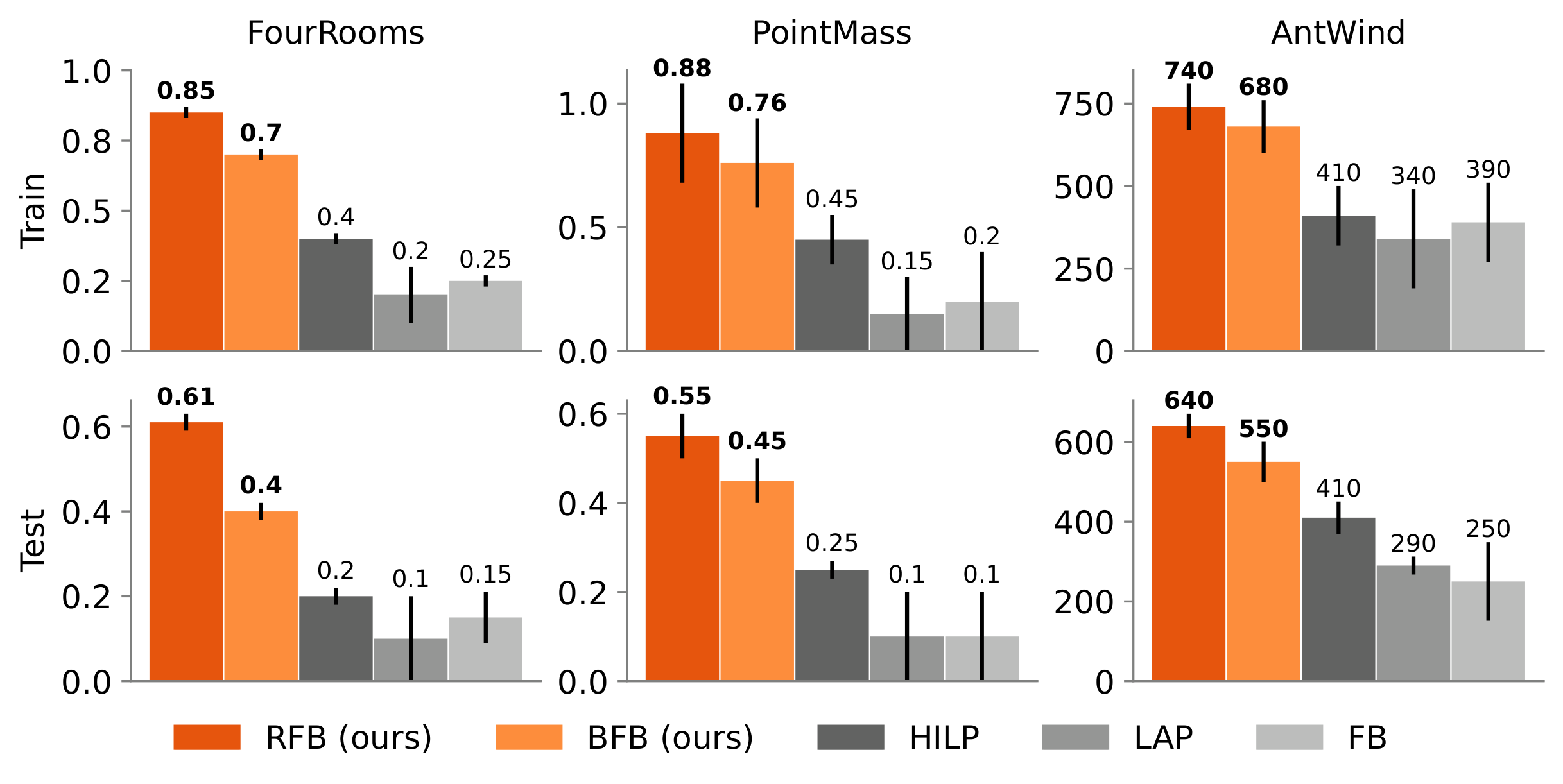
Zero-shot reinforcement learning aims to deploy agents in new environments without test-time fine-tuning.
Behavioral
Foundation Models (BFMs) offer a promising framework, but existing methods fail under dynamics shifts, due
to
interference—they average over different environment dynamics, leading to entangled policy
representations.
We identify this limitation in Forward-Backward (FB) representations, analyze it theoretically and and
propose two solutions:
Belief-FB (BFB), which infers the latent context (dynamics) via belief estimation and conditions
the model
accordingly,
and
Rotation-FB (RFB), which further disentangles policy space by adjusting the prior over \(z_{FB}\).